
Visual concept learning, also known as Text-to-image personalization, is the process of teaching new concepts to a pretrained model. This has numerous applications from product placement to entertainment and personalized design. Here we show that many existing methods can be substantially augmented by adding a personalization step that is (1) specific to the prompt and noise seed, and (2) using two loss terms based on the self- and cross- attention, capturing the identity of the personalized concept. Specifically, we leverage PDM features - previously designed to capture identity - and show how they can be used to improve personalized semantic similarity. We evaluate the benefit that our method gains on top of six different personalization methods, and several base text-to-image models (both UNet- and DiT-based). We find significant improvements even over previous per-query personalization methods.













We present images generated by various personalization methods without our method and with it, including DB, TI, DBlend, CLD, AttnDB, and LoRA, across 4 different backbones (FLUX, SDXL, SD2.1, SD1.5). The left column shows one example of the target concept, and then every pair of columns shows the generated images with and without our method. Each pair uses the same prompt and seed. Adding our method to those personalization approaches yields better performance in text alignment and identity preservation compared to these baselines. Prompts were generated using ChatGPT.














We present images generated by 3 personalization methods (including DB, TI, LoRA) using 3 per-query methods (including AlignIT, PALP, Ours), across 3 different backbones (FLUX, SDXL, SD2.1). Our method demonstrates superior performance in text alignment and identity preservation compared to these per-query methods. Our per-query method, is the only method that successfully generates identity preserved and text-aligned personalized images for these complex queries.
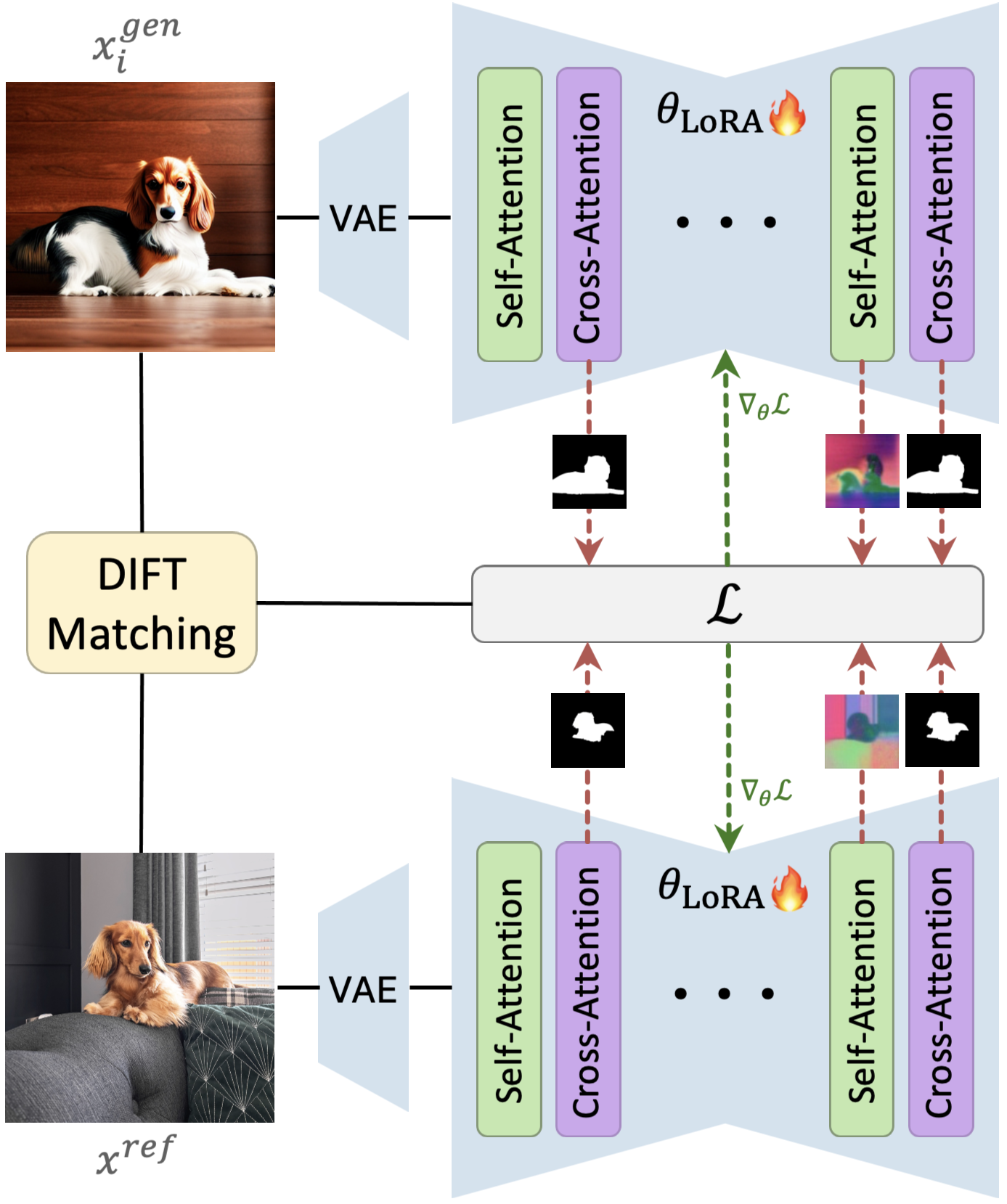
We enhance personalized text-to-image models by computing self- and cross-attention features from a single denoising step of a generated image \( x^{\text{gen}} \) and a reference image \( x^{\text{ref}} \). Using DIFT, we match these features and define losses \( \mathcal{L}_{\text{SA}} \), \( \mathcal{L}_{\text{CA}} \), and \( \mathcal{L}_{\text{LDM}} \), which are combined to update the personalization tuning parameters via gradient descent.
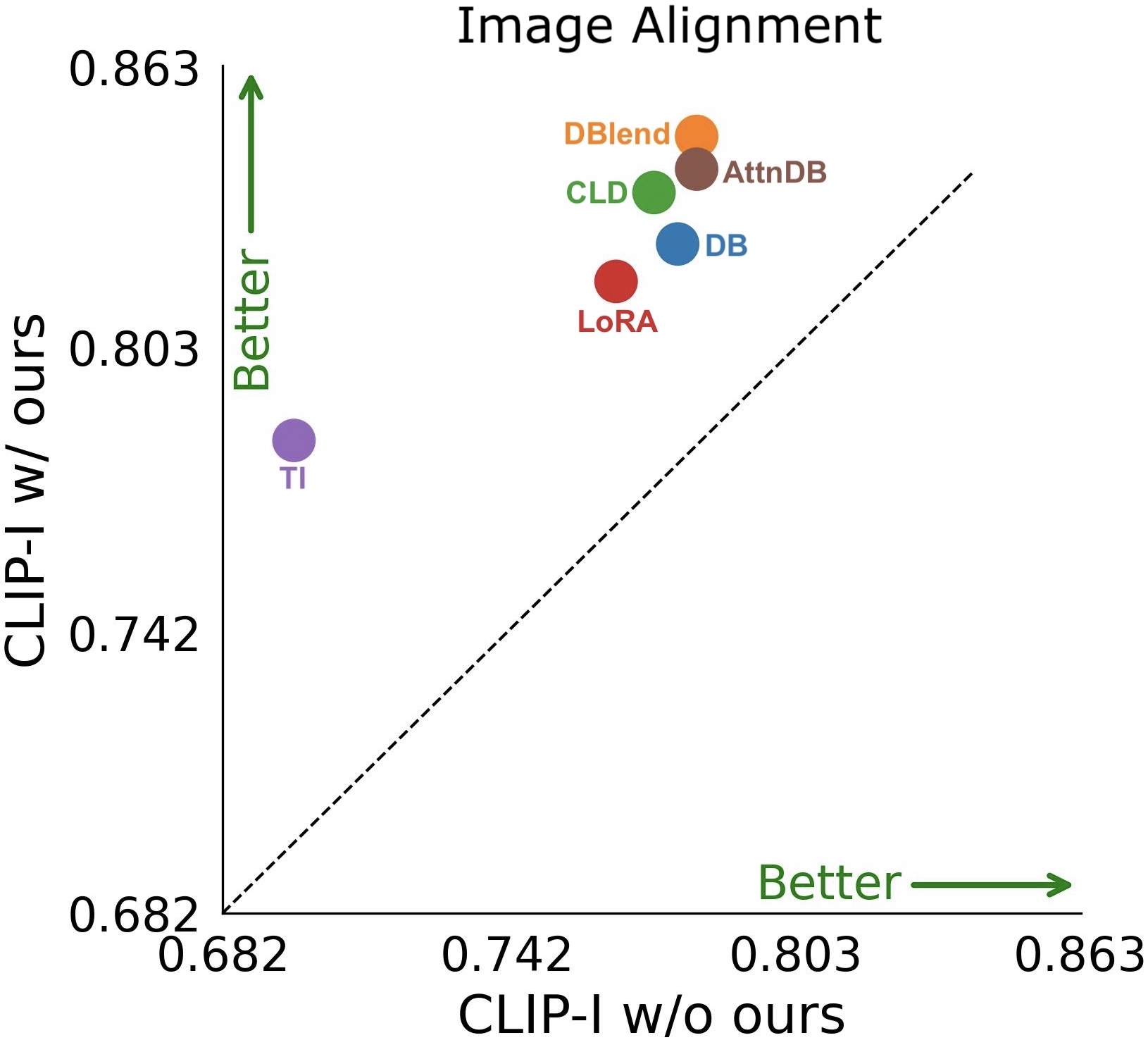
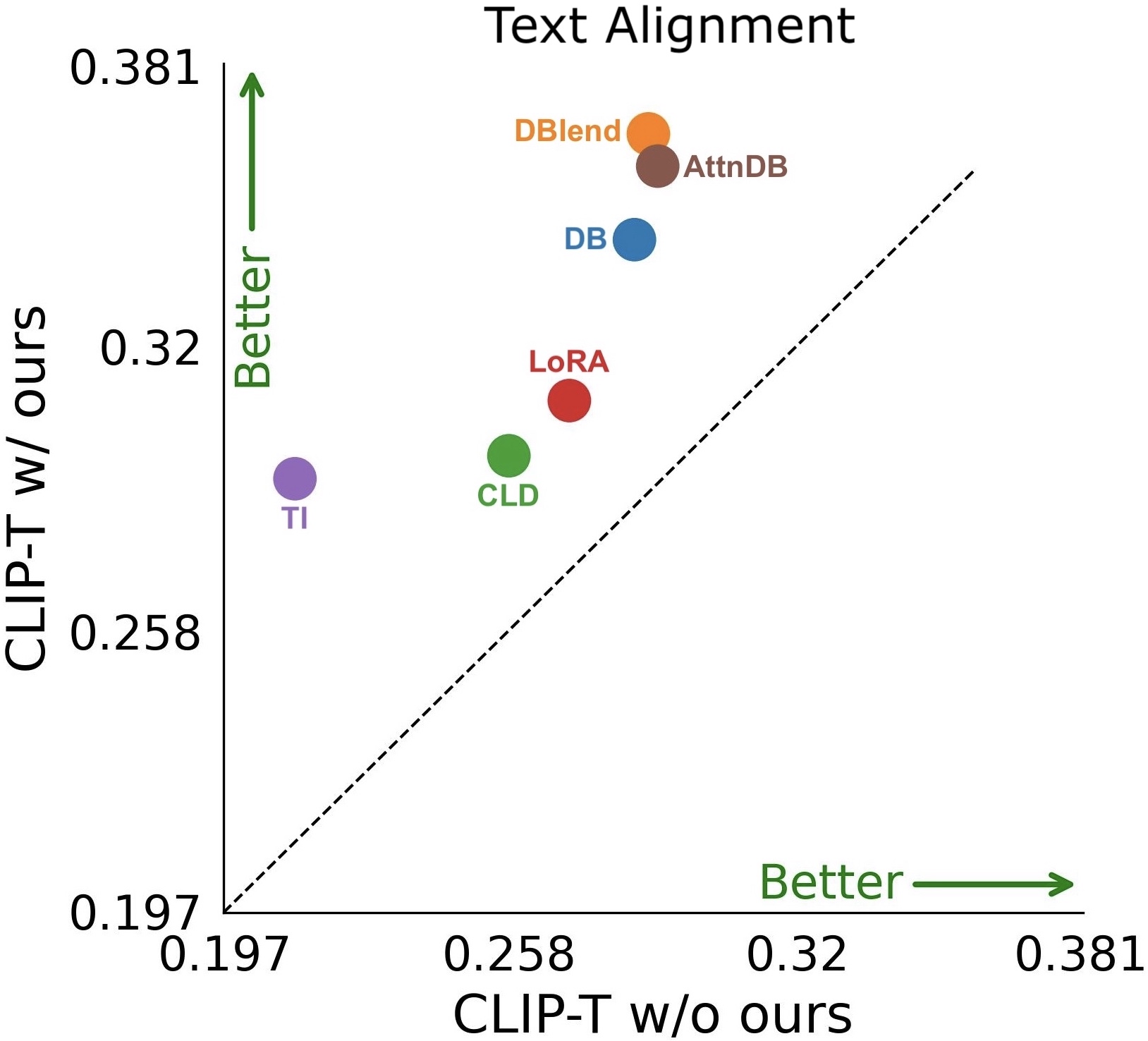
Effect of adding our method to baseline personalization models. shown are image alignment (left) and text alignment (right) of several personalization approaches with (w/) and without (w/o) the integration of our method.
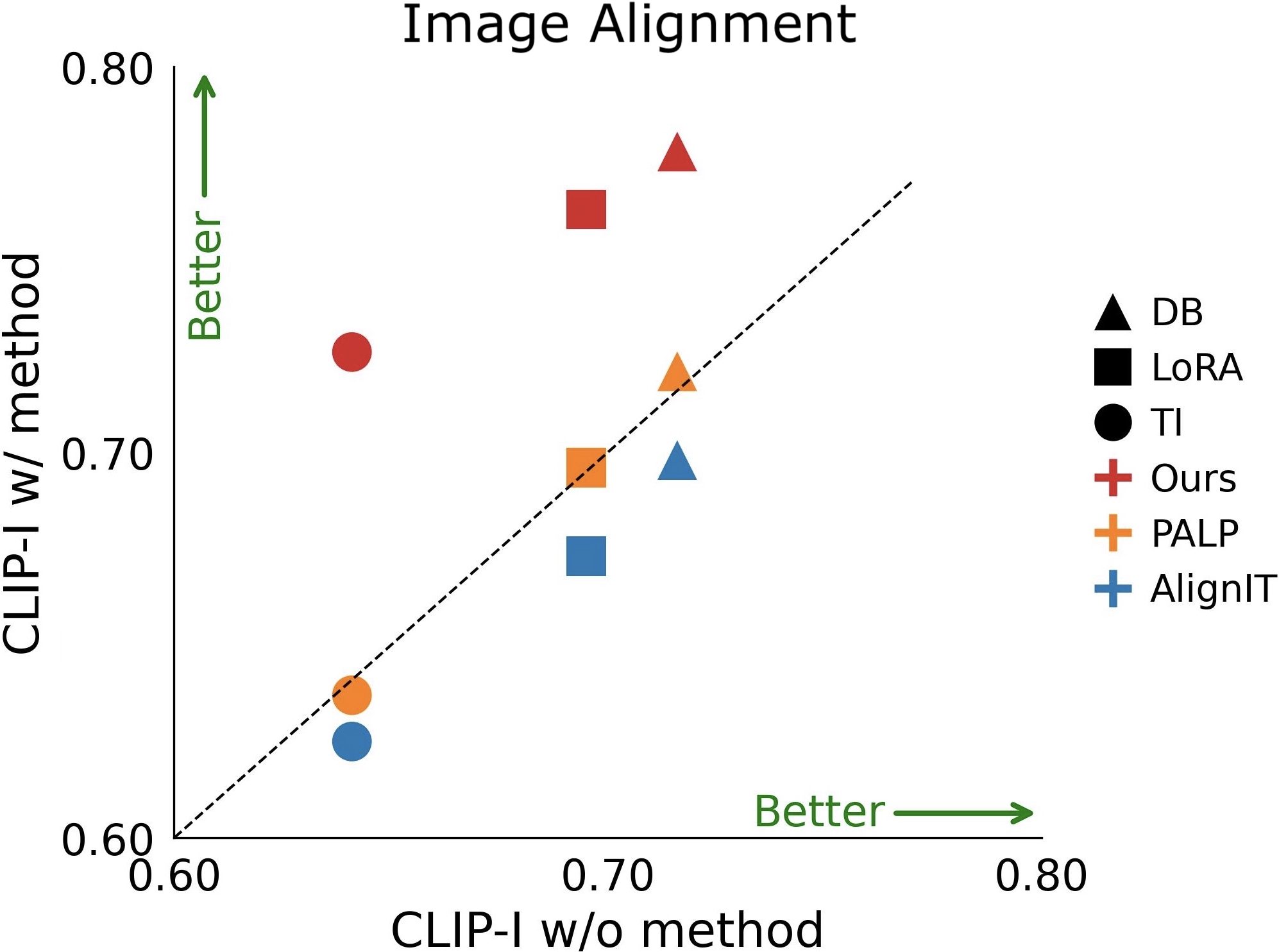
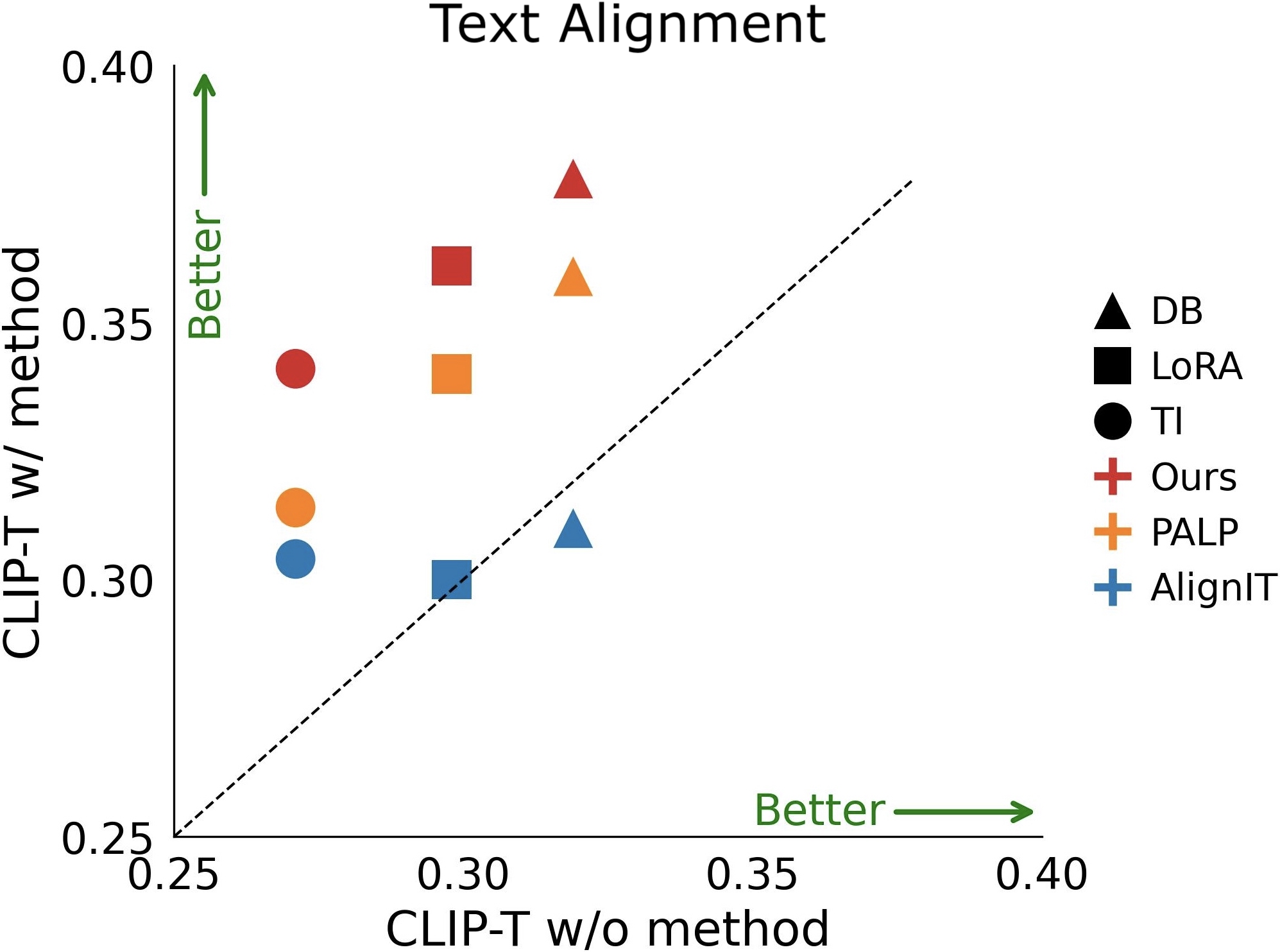
Quantitative Comparison with previous per-query methods. Image alignment (left) and text alignment (right) of various personalization approaches (including, DB, LoRA, and TI), with (w/) and without (w/o) the integration of different per-query methods (including, AlignIT, PALP, and Ours).
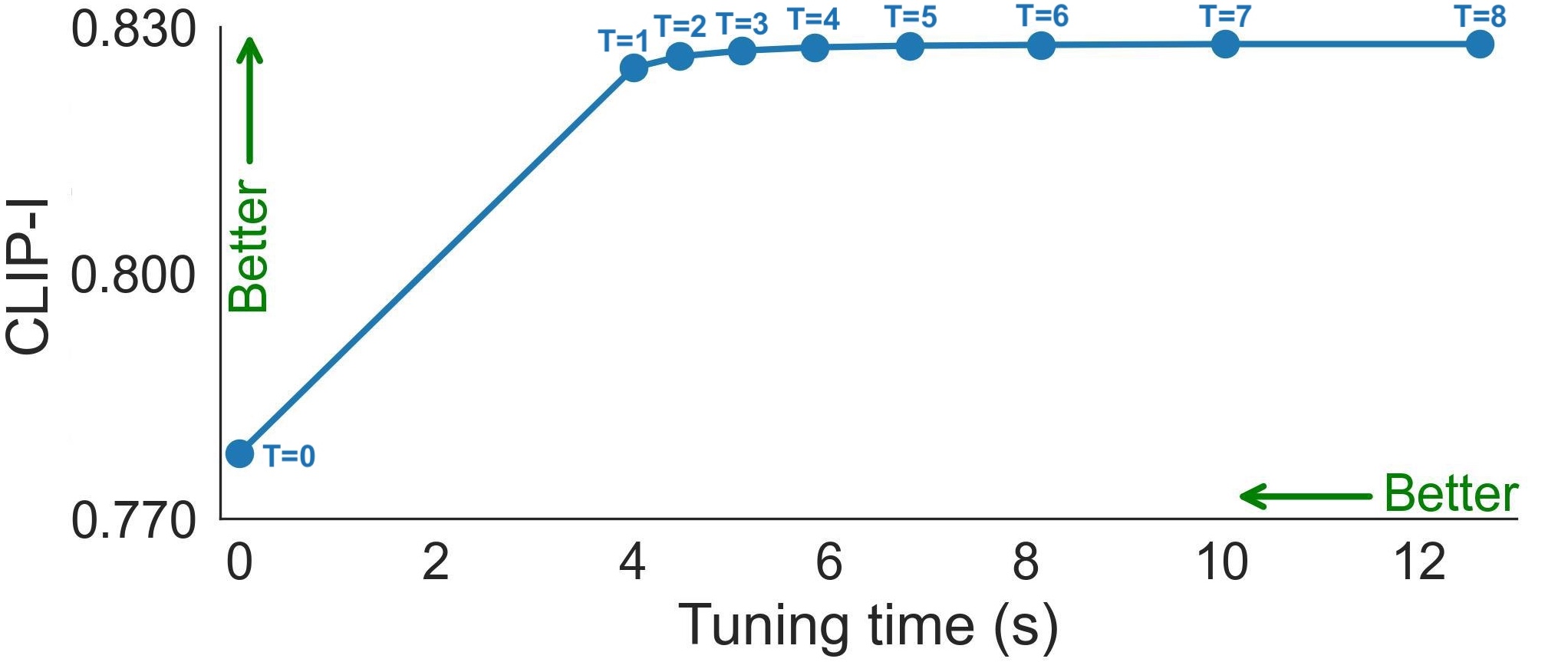
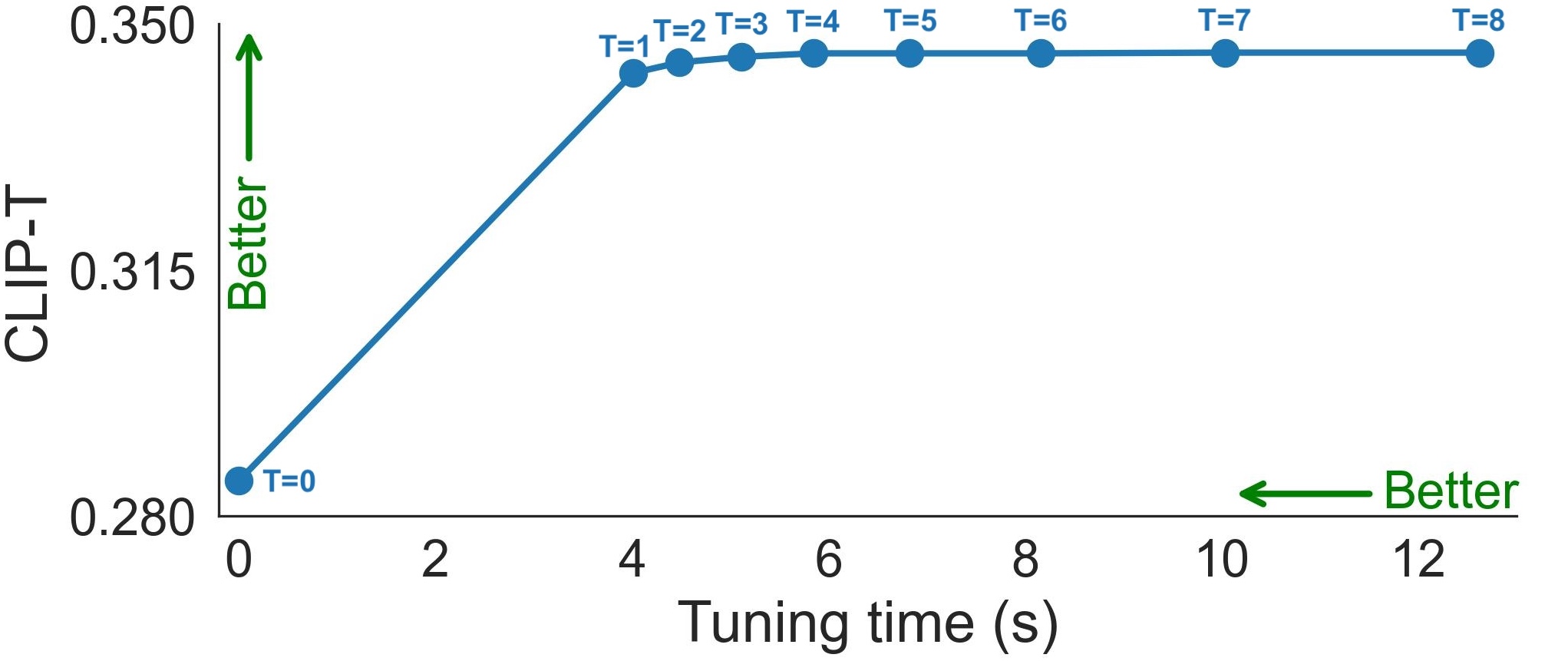
Quality-vs-time Tradeoff. Figures show the CLIP-I (left) and CLIP-T (right) metrics as a function of fine-tuning duration. The duration is longer when using more features that are collected throughout the denoising path. \( T \) is the number of feature maps using to compute the losses.
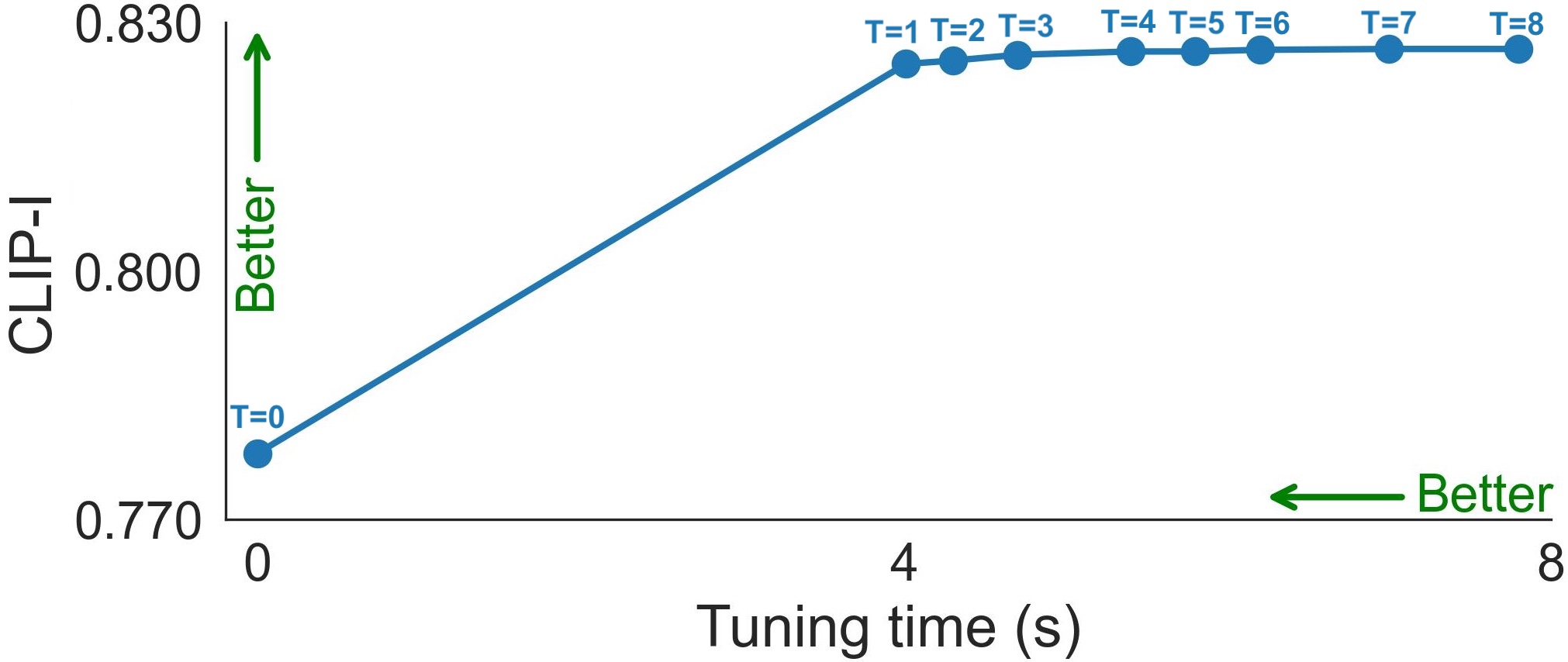
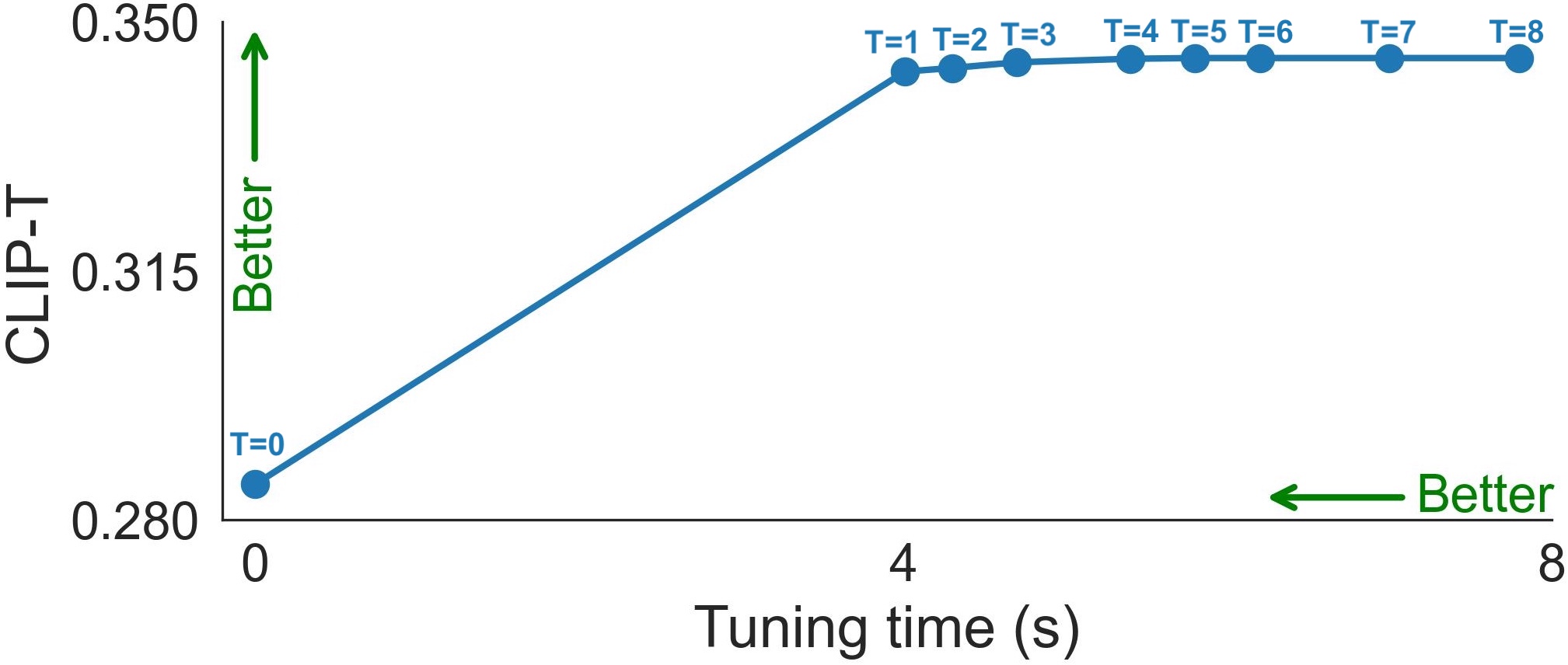
Quality-vs-time Tradeoff. Figures show the CLIP-I (left) and CLIP-T (right) metrics as a function of fine-tuning duration. The duration is longer when using more SA features that are collected throughout the denoising path. \( T \) is the number of feature maps using to compute the losses.
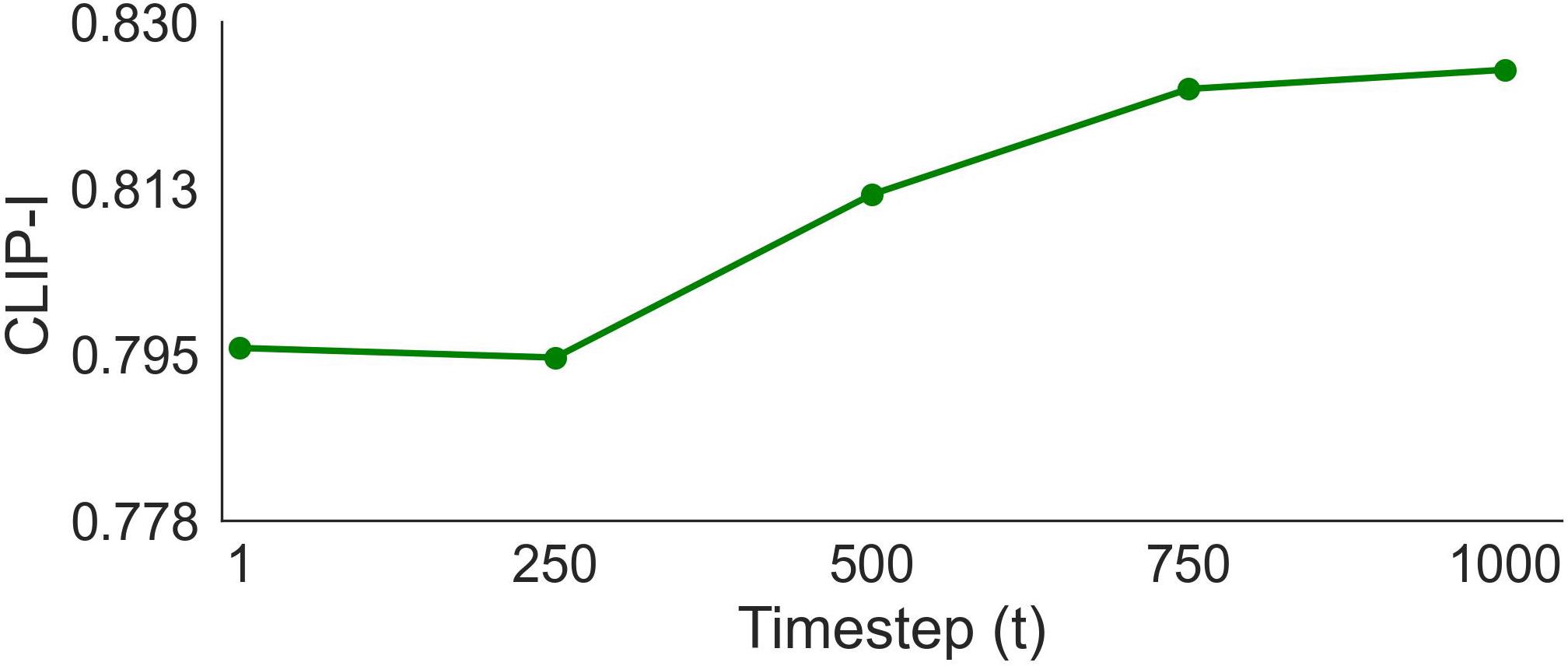
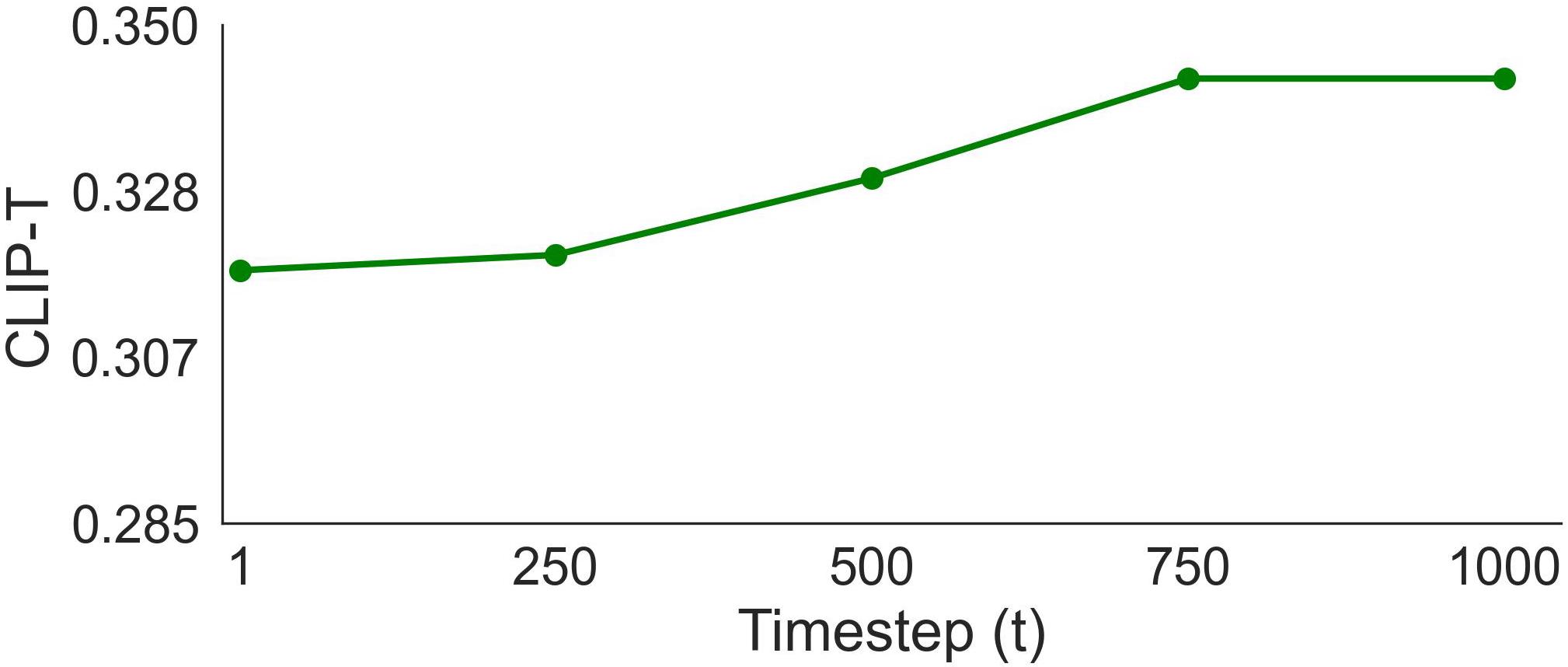
Noise weight Ablation Study. Sensitivity of CLIP-I and CLIP-T metrics to the magnitude of the noise, in terms of the \( t \) parameter used when calculating features.
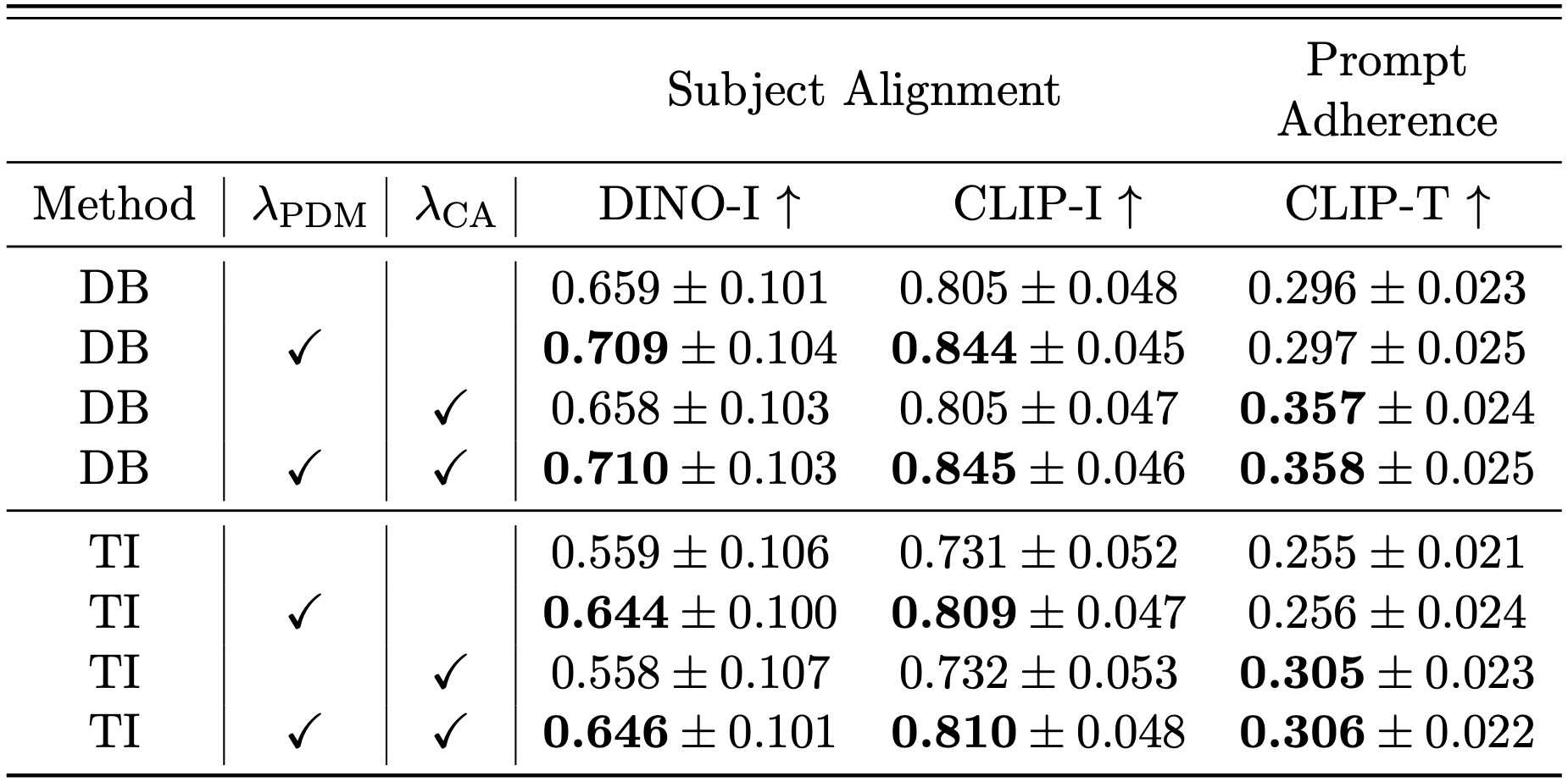
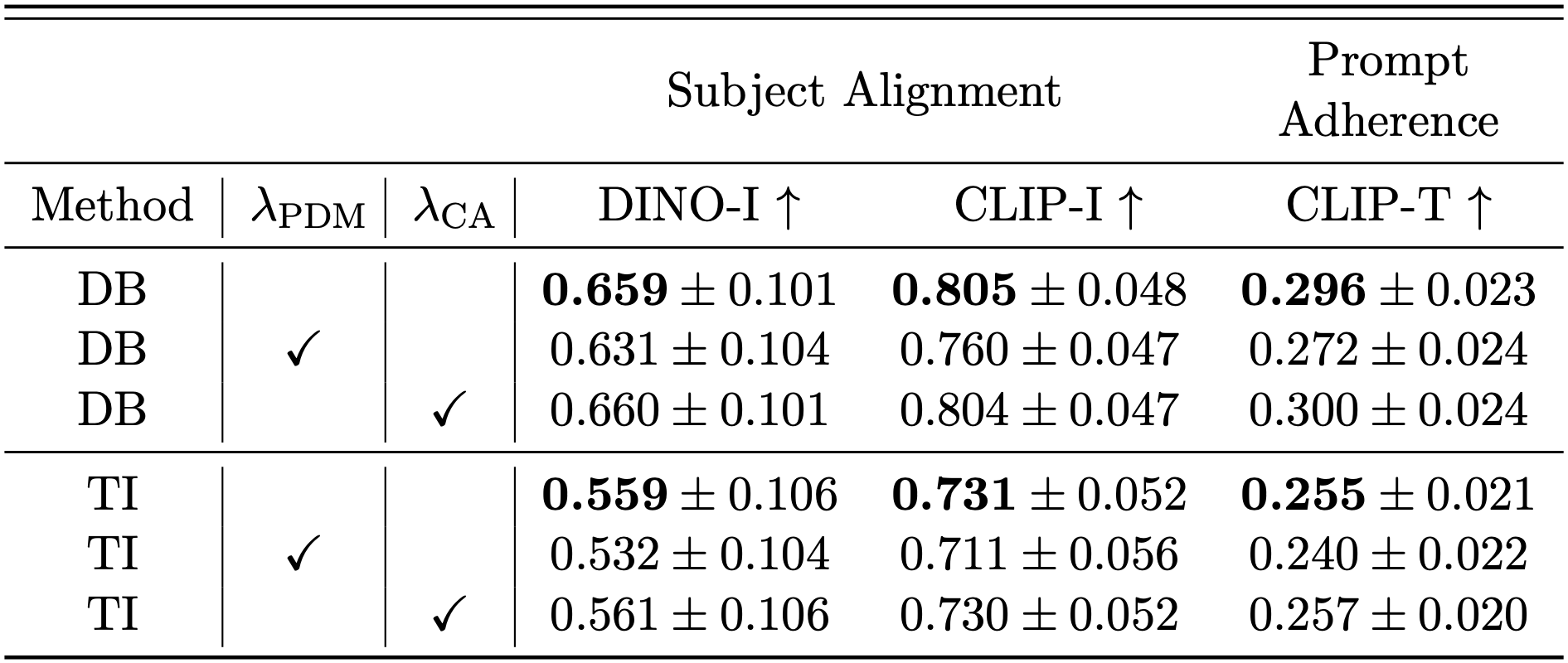
Per-loss contribution ablation study. We investigate the contribution of each loss in our proposed method. Testing across different methods, leveraging SD1.5 as backbone, and using a fixed \( \lambda_{\text{PDM}}=1,\lambda_{\text{CA}}=1 \) values. \( \mathcal{L}_{\text{PDM}} \) provides superior subject alignment, and \( \mathcal{L}_{\text{CA}} \) results superior prompt-adherence. Incorporating both provides superior results in both aspects.
Stage-wise loss effectiveness ablation study. We examine the effectiveness of \( \mathcal{L}_{\text{SA}} \) and \( \mathcal{L}_{\text{CA}} \) throughout training rather than post-training, with two prominent methods, utilizing SD1.5 as backbone, with \( \lambda_{\text{PDM}}=1,\lambda_{\text{CA}}=1 \). We observe inferior results compared to post-training integration, and equal/inferior results compared to the baseline. This quantitatively support that certain losses become effective only after the model reaches a certain state.
If you find our work useful, please cite our paper:
@article{malca2025per,
title = {Per-Query Visual Concept Learning},
author = {Malca, Ori and Samuel, Dvir and Chechik, Gal},
journal = {arXiv preprint arXiv:2508.09045},
year = {2025}
}